@本文链接
一. 数据流图
本节将脱离TensorFlow的语境,介绍一些数据流图的基础知识,内容包括节点、边和节点依赖关系的定义。此外,为对一些关键原理进行解释。
1.1 数据流图
- 为什么要用数据流图的方式定义tensorflow程序的计算?
借助TensorFlow API用代码描述的数据流图是每个TensorFlow程序的核心。毫不意外,数据流图这种特殊类型的有向图正是用于定义计算结构的。在TensorFlow中,数据流图本质上是一组链接在一起的函数,每个函数都会将其输出传递给0个、1个或更多位于这个级联链上的其他函数。按照这种方式,用户可利用一些很小的、为人们所充分理解的数学函数构造数据的复杂变换。下面来看一个比较简单的例子。
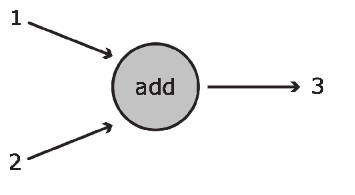 上图展示了可完成基本加法运算的数据流图。在该图中,加法运算是用圆圈表示的,它可接收两个输入(以指向该函数的箭头表示),并将1和2之和3输出(对应从该函数引出的箭头)。该函数的运算结果可传递给其他函数,也可直接返回给客户。
该数据流图可用如下简单公式表示:
上图展示了可完成基本加法运算的数据流图。在该图中,加法运算是用圆圈表示的,它可接收两个输入(以指向该函数的箭头表示),并将1和2之和3输出(对应从该函数引出的箭头)。该函数的运算结果可传递给其他函数,也可直接返回给客户。
该数据流图可用如下简单公式表示:
f(1,2)=1+2=3
上面的例子解释了在构建数据流图时,两个基础构件——节点和边是如何使用的。下面回顾节点和边的基本性质:
- 节点(node) :在数据流图的语境中,节点通常以圆圈、椭圆和方框表示,代表了对数据所做的运算或某种操作。在上例中,“add”对应于一个孤立节点。
-
边(edge) :对应于向Operation传入和从Operation传出的实际数值,通常以箭头表示。在“add”这个例子中,输入1和2均为指向运算节点的边,而输出3则为从运算节点引出的边。可从概念上将边视为不同Operation之间的连接,因为它们将信息从一个节点传输到另一个节点。 下面来看一个更有趣的例子。
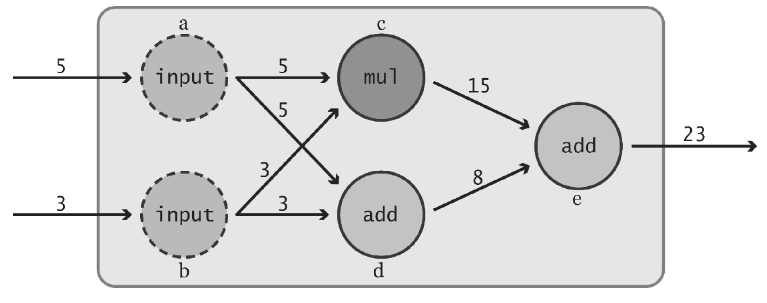 相比之前的例子,上图所示的数据流图略复杂。由于数据是从左侧流向右侧的(如箭头方向所示),因此可从最左端开始对这个数据流图进行分析:
相比之前的例子,上图所示的数据流图略复杂。由于数据是从左侧流向右侧的(如箭头方向所示),因此可从最左端开始对这个数据流图进行分析: - 最开始时,可看到两个值5和3流入该数据流图。它们可能来自另一个数据流图,也可能读取自某个文件,或是由客户直接输入。
- 这些初始值被分别传入两个明确的“input”节点(图中分别以a、b标识)。这些“input”节点的作用仅仅是传递它们的输入值——节点a接收到输入值5后,将 同样的数值输出给节点c和节点d,节点b对其输入值3也完成同样的动作。
- 节点c代表乘法运算。它分别从节点a和b接收输入值5和3,并将运算结果15输出到节点e。与此同时,节点d对相同的两个输入执行加法运算,并将计算结 果8传递给节点e。
- 最后,该数据流图的终点——节点e是另一个“add”节点。它接收输入值15和8,将两者相加,然后输出该数据流图的最终结果23。 下面说明为何上述图形表示看起来像是一组公式:
a=input1 ; b=input2 c=a*b; d=a+b e=c+d
当a=5、b=3时,若要求解e,只需依次代入上述公式。
a=5 ; b=3 e=ab+(a+b) e=53+(5+3)=23
经过上述步骤,便完成了计算。 这里有一些概念值得重点说明:
- 上述使用“input”节点的模式十分有用,因为这使得我们能够将单个输入值传递给大量后继节点。如果不这样做,客户(或传入这些初值的其他数据源)便不得不将输入值显式传递给数据流图中的多个节点。按照这种模式,客户只需保证一次性传入恰当的输入值,而如何对这些输入重复使用的细节便被隐藏起 来。稍后,我们将对数据流图的抽象做更深入的探讨。
- 突击小测验。哪一个节点将首先执行运算?是乘法节点c还是加法节点d?答案是:无从知晓。仅凭上述数据流图,无法推知c和d中的哪一个节点将率先执行。有的读者可能会按照从左到右、自上而下的顺序阅读该数据流图,从而做出节点c先运行的假设。但我们需要指出,在该数据流图中,将节点d绘制在c的上方也未尝不可。也可能有些读者认为这些节点会并发执行,但考虑到各种实现细节或硬件的限制,实际情况往往并非总是如此。实际上,最好的方式是将它们的执行视为相互独立。由于节点c并不依赖于来自节点d的任何信息,所以节点c在完成自身的运算时无需关心节点d的状态如何。反之亦然,节点d也不需要任何来自节点c的信息。
稍后,还将对节点依赖关系进行更深入的介绍。
接下来,对上述数据流图稍做修改。
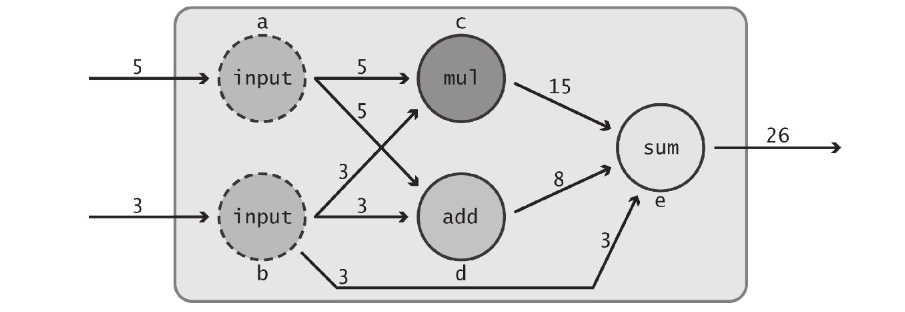 主要的变化有两点:
1)来自节点b的“input”值3现在也传递给了节点e。
2)节点e中的函数“add”被替换为“sum”,表明它可完成两个以上的数的加法运算。
你已经注意到,上图在看起来被其他节点“隔离”的两个节点之间添加了一条边。一般而言,任何节点都可将其输出传递给数据流图中的任意后继节点,而无论这两者之间发生了多少计算。数据流图甚至可以拥有下图所示的结构,它仍然是完全合法的。
主要的变化有两点:
1)来自节点b的“input”值3现在也传递给了节点e。
2)节点e中的函数“add”被替换为“sum”,表明它可完成两个以上的数的加法运算。
你已经注意到,上图在看起来被其他节点“隔离”的两个节点之间添加了一条边。一般而言,任何节点都可将其输出传递给数据流图中的任意后继节点,而无论这两者之间发生了多少计算。数据流图甚至可以拥有下图所示的结构,它仍然是完全合法的。
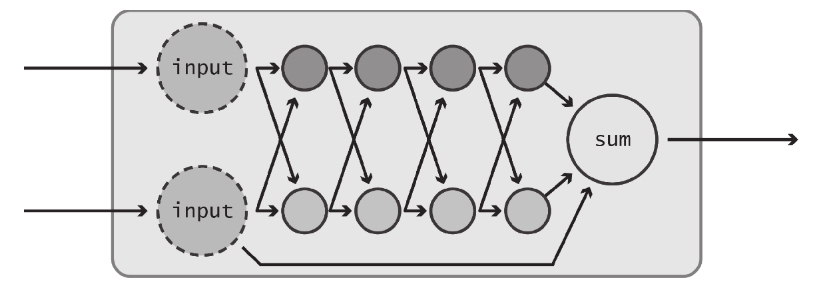 通过这两个数据流图,想必你已能够初步感受到对数据流图的输入进行抽象所带来的好处。我们能够对数据流图中内部运算的精确细节进行操控,但客户只需了解将何种信息传递给那两个输入节点则可。我们甚至可以进一步抽象,将上述数据流图表示为如下的黑箱。
通过这两个数据流图,想必你已能够初步感受到对数据流图的输入进行抽象所带来的好处。我们能够对数据流图中内部运算的精确细节进行操控,但客户只需了解将何种信息传递给那两个输入节点则可。我们甚至可以进一步抽象,将上述数据流图表示为如下的黑箱。
 这样,我们便可将整个节点序列视为拥有一组输入和输出的离散构件。这种抽象方式使得对级联在一起的若干个运算组进行可视化更加容易,而无需关心每个部件的具体细节。
这样,我们便可将整个节点序列视为拥有一组输入和输出的离散构件。这种抽象方式使得对级联在一起的若干个运算组进行可视化更加容易,而无需关心每个部件的具体细节。
1.2 节点之间的依赖关系
在数据流图中,节点之间的某些类型的连接是不被允许的,最常见的一种是将造成循环依赖(circular dependency)的连接。为理解“循环依赖”这个概念,需要先理解何为“依赖关系”。再次观察下面的数据流图。
循环依赖这个概念其实非常简单:对于任意节点A,如果其输出对于某个后继节点B的计算是必需的,则称节点A为节点B的依赖节点。如果某个节点A和节点B彼此不需要来自对方的任何信息,则称两者是独立的。为对此进行可视化,首先观察当乘法节点c出于某种原因无法完成计算时会出现何种情况。
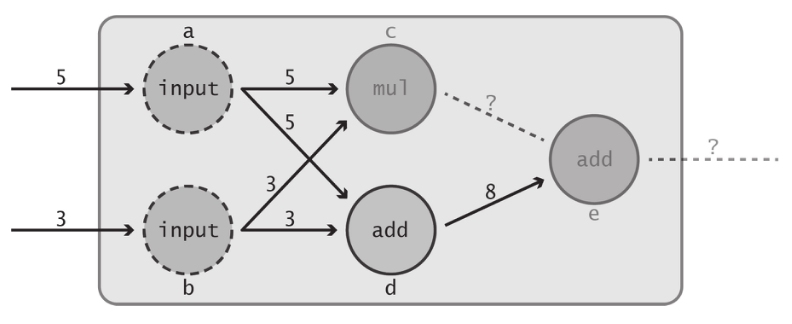 可以预见,由于节点e需要来自节点c的输出,因此其运算无法执行,只能无限等待节点c的数据的到来。容易看出,节点c和节点d均为节点e的依赖节点,因为它们均将信息直接传递到最后的加法函数。然而,稍加思索便可看出节点a和节点b也是节点e的依赖节点。如果输入节点中有一个未能将其输出传递给数据流图中的下一个函数,情形会怎样?
可以预见,由于节点e需要来自节点c的输出,因此其运算无法执行,只能无限等待节点c的数据的到来。容易看出,节点c和节点d均为节点e的依赖节点,因为它们均将信息直接传递到最后的加法函数。然而,稍加思索便可看出节点a和节点b也是节点e的依赖节点。如果输入节点中有一个未能将其输出传递给数据流图中的下一个函数,情形会怎样?
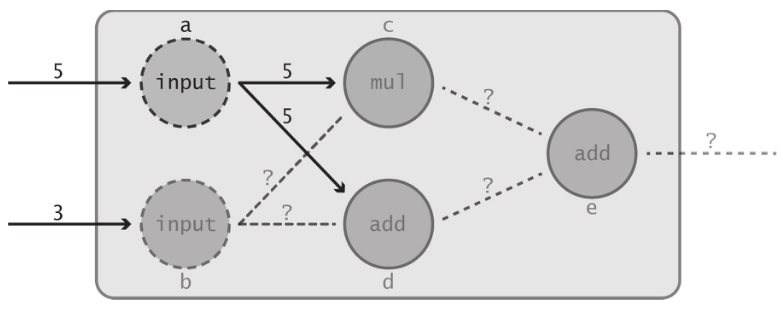 可以看出,若将输入中的某一个移除,会导致数据流图中的大部分运算中断,从而表明依赖关系具有传递性。即,若A依赖于B,而B依赖于C,则A依赖于C。在本例中,最终节点e依赖于节点c和节点d,而节点c和节点d均依赖于输入节点b。因此,最终节点e也依赖于输入节点b。同理可知节点e也依赖于输入节点
a。此外,还可对节点e的不同依赖节点进行区分:
可以看出,若将输入中的某一个移除,会导致数据流图中的大部分运算中断,从而表明依赖关系具有传递性。即,若A依赖于B,而B依赖于C,则A依赖于C。在本例中,最终节点e依赖于节点c和节点d,而节点c和节点d均依赖于输入节点b。因此,最终节点e也依赖于输入节点b。同理可知节点e也依赖于输入节点
a。此外,还可对节点e的不同依赖节点进行区分:
- 称节点e直接依赖 于节点c和节点d。即为使节点e的运算得到执行,必须有直接来自节点c和节点d的数据。
- 称节点e间接依赖 于节点a和节点b。这表示节点a和节点b的输出并未直接传递到节点e,而是传递到某个(或某些)中间节点,而这些中间节点可能是节点e的直接依赖节点,也可能是间接依赖节点。这意味着一个节点可以是被许多层的中间节点相隔的另一个节点的间接依赖节点(且这些中间节点中的每一个也
是后者的依赖节点)
最后来观察将数据流图的输出传递给其自身的某个位于前端的节点时会出现何种情况。
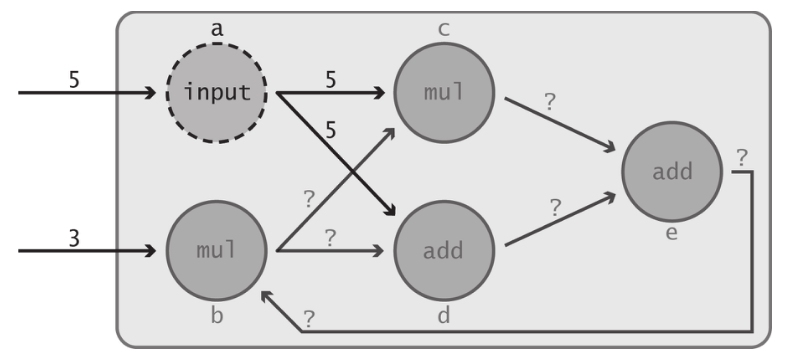 不幸的是,上面的数据流图看起来无法工作。我们试图将节点e的输出送回节点b,并希望该数据流图的计算能够循环进行。这里的问题在于节点e现在变为节点b的直接依赖节点;而与此同时,节点e仍然依赖于节点b(前文已说明过)。其结果是节点b和节点e都无法得到执行,因为它们都在等待对方计算的完成。
不幸的是,上面的数据流图看起来无法工作。我们试图将节点e的输出送回节点b,并希望该数据流图的计算能够循环进行。这里的问题在于节点e现在变为节点b的直接依赖节点;而与此同时,节点e仍然依赖于节点b(前文已说明过)。其结果是节点b和节点e都无法得到执行,因为它们都在等待对方计算的完成。 - 真的就没办法把流图运行下去吗?换句话说,这个流图虽然陷入死锁,但是一个扰动稳定的系统,即只要有一次b有了赋值,系统将会永久工作。
也许你非常聪明,决定将传递给节点b或节点e的值设置为某个初始状态值。毕竟,这个数据流图是受我们控制的。不妨假设节点e的输出的初始状态值为1,使其先工作起来,最后看看1是否稳妥。
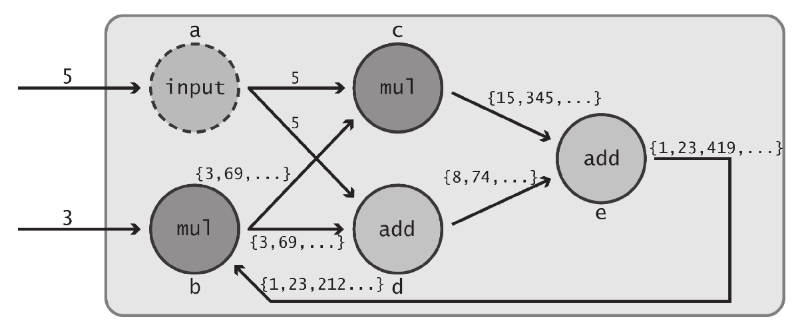 上图给出了经过几轮循环各数据流图中各节点的状态。新引入的依赖关系制造了一个无穷反馈环,且该数据流图中的大部分边都趋向于无穷大。
事实上,出于不限于上述的多种原因,对于像TensorFlow这样的软件,这种类型的无限循环是非常不利的:
上图给出了经过几轮循环各数据流图中各节点的状态。新引入的依赖关系制造了一个无穷反馈环,且该数据流图中的大部分边都趋向于无穷大。
事实上,出于不限于上述的多种原因,对于像TensorFlow这样的软件,这种类型的无限循环是非常不利的: - 由于数据流图中存在无限循环,因此程序无法以优雅的方式终止。
- 依赖节点的数量变为无穷大,因为每轮迭代都依赖于之前的所有轮次的迭代。不幸的是,在统计依赖关系时,每个节点都不会只被统计一次,每当其输出发生变化时,它便会被再次记为依赖节点。这就使得追踪依赖信息变得不可能,而出于多种原因(详见本节的最后一部分),这种需求是至关重要的。
- 你经常会遇到这样的情况:被传递的值要么在正方向变得非常大(从而导致上溢),要么在负方向变得非常大(导致下溢),或者非常接近于0(使得每轮迭代在加法上失去意义)
基于上述考虑,在TensorFlow中,真正的循环依赖关系是无法表示的,这并非坏事。在实际使用中,完全可通过对数据流图进行有限次的复制,然后将它们并排放置,并将代表相邻迭代轮次的副本的输出与输入串接。该过程通常被称为数据流图的“展开”(unrolling)。第6章还将对此进行更为详细的介绍。为了以图形化的方式展示数据流图的展开效果,下面给出一个将循环依赖展开5次后的数据流图。
 对这个数据流图进行分析,便会发现这个由各节点和边构成的序列等价于将之前的数据流图遍历5次。请注意原始输入值(以数据流图顶部和底部的跳跃箭头表示)是传递给数据流图的每个副本的,因为代表每轮迭代的数据流图的每个副本都需要它们。按照这种方式将数据流图展开,可在保持确定性计算的同时
模拟有用的循环依赖。
既然我们已理解了节点的依赖关系,接下来便可分析为什么追踪这种依赖关系十分有用。
对这个数据流图进行分析,便会发现这个由各节点和边构成的序列等价于将之前的数据流图遍历5次。请注意原始输入值(以数据流图顶部和底部的跳跃箭头表示)是传递给数据流图的每个副本的,因为代表每轮迭代的数据流图的每个副本都需要它们。按照这种方式将数据流图展开,可在保持确定性计算的同时
模拟有用的循环依赖。
既然我们已理解了节点的依赖关系,接下来便可分析为什么追踪这种依赖关系十分有用。
- 不妨假设在之前的例子中,我们只希望得到节点c(乘法节点)的输出。我们已经定义了完整的数据流图,其中包含独立于节点c和节点e(出现在节点c的后方)的节点d,那么是否必须执行整个数据流图的所有运算,即便并不需要节点d和节点e的输出? 答案当然是否定的。观察该数据流图,不难发现,如果只需要节点c的输出,那么执行所有节点的运算便是浪费时间。但这里的问题在于:如何确保计算机只对必要的节点执行运算,而无需手工指定?答案是:利用节点之间的依赖关系! 这背后的概念相当简单,我们唯一需要确保的是为每个节点的直接(而非间接)依赖节点维护一个列表。 可从一个空栈开始,它最终将保存所有我们希望运行的节点。从你希望获得其输出的节点开始。显然它必须得到执行,因此令其入栈。接下来查看该输出节点的依赖节点列表,这意味着为计算输出,那些节 点必须运行,因此将它们全部入栈。然后,对所有那些节点进行检查,看它们的直接依赖节点有哪些,然后将它们全部入栈。继续这种追溯模式,直到数据流图中的所有依赖节点均已入栈。按照这种方式,便可保证我们获得运行该数据流图所需的全部节点,且只包含所有必需的节点。此外,利用上述栈结构,可对 其中的节点进行排序,从而保证当遍历该栈时,其中的所有节点都会按照一定的次序得到运行。唯一需要注意的是需要追踪哪些节点已经完成了计算,并将它们的输出保存在内存中,以避免对同一节点反复计算。 按照这种方式,便可确保计算量尽可能地精简,从而在规模较大的数据流图上节省以小时计的宝贵处理 时间。
二. 在tensorflow中定义数据流图
不同的模型在TensorFlow中的定义过程却遵循着相似的模式。当掌握了各种数学概念,并学会如何实现它们时,对TensorFlow核心工作模式的理解将有助于你脚踏实地开展工作。幸运的是,这个工作流非常容易记忆,它只包含两个步骤:
- 1)定义数据流图。
- 2)运行数据流图(在数据上)。
有一个显而易见的道理,如果数据流图不存在,那么肯定无法运行它。头脑中有这种概念是很有必要的,因为当你编写代码时会发现TensorFlow功能是如此丰富。每次只需关注上述工作流的一部分,有助于更周密地组织自己的代码,并有助于明确接下来的工作方向。
本节将专注于讲述在TensorFlow中定义数据流图的基础知识,下一节将介绍当数据流图创建完毕后如何运行。最后,我们会将这两个步骤进行衔接,并展示如何创建在多次运行中状态不断发生变化并接收不同数据的数据流图。
2.1 利用tensorflow构建一个简单的数据流图
还是一开始的那个数据流图,现在我们的目标是如何构建她。
用于表示该数据流图的TensorFlow代码如下所示:
import tensorflow as tf
a=tf.constant(5,name="input_a")
b=tf.constant(3,name="input_b")
c=tf.mul(a,b,name="mul_c")
d=tf.add(a,b,name="add_d")
e=tf.add(c,d,name="add_e")
下面尝试解析一下这段代码:
import tensorflow as tf
这条语句的作用是导入TensorFlow库,并赋予它一个别名——tf。按照惯例,人们通常都是以这种形式导入TensorFlow的,因为在使用该库中的各种函数时,键入“tf”要比键入完整的“tensorflow”容易得多。 接下来研究前两行变量赋值语句:
a=tf.constant(5,name="input_a")
b=tf.constant(3,name="input_b")
这里定义了“input”节点a和b。语句第一次引用了TensorFlow Operation:tf.constant()。在TensorFlow中,数据流图中的每个节点都被称为一个Operation(简记为Op)。各Op可接收0个或多个Tensor对象作为输入,并输出0个或多个Tensor对象。要创建一个Op,可调用与其关联的Python构造方法,在本例中,tf.constant()创建了一个“常量”Op,它接收单个张量值,然后将同样的值输出给与其直接连接的节点。为方便起见,该函数自动将标量值6和3转换为Tensor对象。此外,我们还为 这个构造方法传入了一个可选的字符串参数name,用于对所创建的节点进行标识。 如果暂时还无法充分理解什么是Operation,什么是Tensor对象,请不必担心,稍后还会对这些概念进行详细介绍。
c=tf.mul(a,b,name="mul_c")
d=tf.add(a,b,name="add_d")
这两个语句定义了数据流图中的另外两个节点,而且它们都使用了之前定义的节点a和b。节点c使用了tf.mul Op,它接收两个输入,然后将它们的乘积输出。类似地,节点d使用了tf.add,该Op可将它的两个输入之和输出。对于这些Op,我们均传入了name参数(今后还将有大量此类用法)。请注意,无需专门对数据流图中的边进行定义,因为在Tensorflow中创建节点时已包含了相应的Op完成计算所需的全部输入,TensorFlow会自动绘制必要的连接。
e=tf.add(c,d,name="add_e")
最后的这行代码定义了数据流图的终点e,它使用tf.add的方式与节点d是一致的。区别只在于它的输入来自节点c和节点d,这与数据流图中的描述完全一致。 通过上述代码,便完成了第一个小规模数据流图的完整定义。如果在一个Python脚本或shell中执行上述代码,它虽然可以运行,但实际上却不会有任何实质性的结果输出。请注意,这只是整个流程的数据流图定义部分,要想体验一个数据流图的运行效果,还需在上述代码之后添加两行语句,以将数据流图终点的结果输出。
import tensorflow as tf
a=tf.constant(5,name="input_a")
b=tf.constant(3,name="input_b")
c=tf.mul(a,b,name="mul_c")
d=tf.add(a,b,name="add_d")
e=tf.add(c,d,name="add_e")
sess=tf.Session()
sess.run(e)
Session对象在运行时负责对数据流图进行监督,并且是运行数据流图的主要接口。在TensorFlow中,如果希望运行自己的代码,必须定义一个Session对象。上述代码将Session对象赋给了变量sess,以便后期能够对其进行访问。
如果在某个交互环境中运行这些代码,如Python shell或Jupyter/iPython Notebook,则可看到正确的输出:
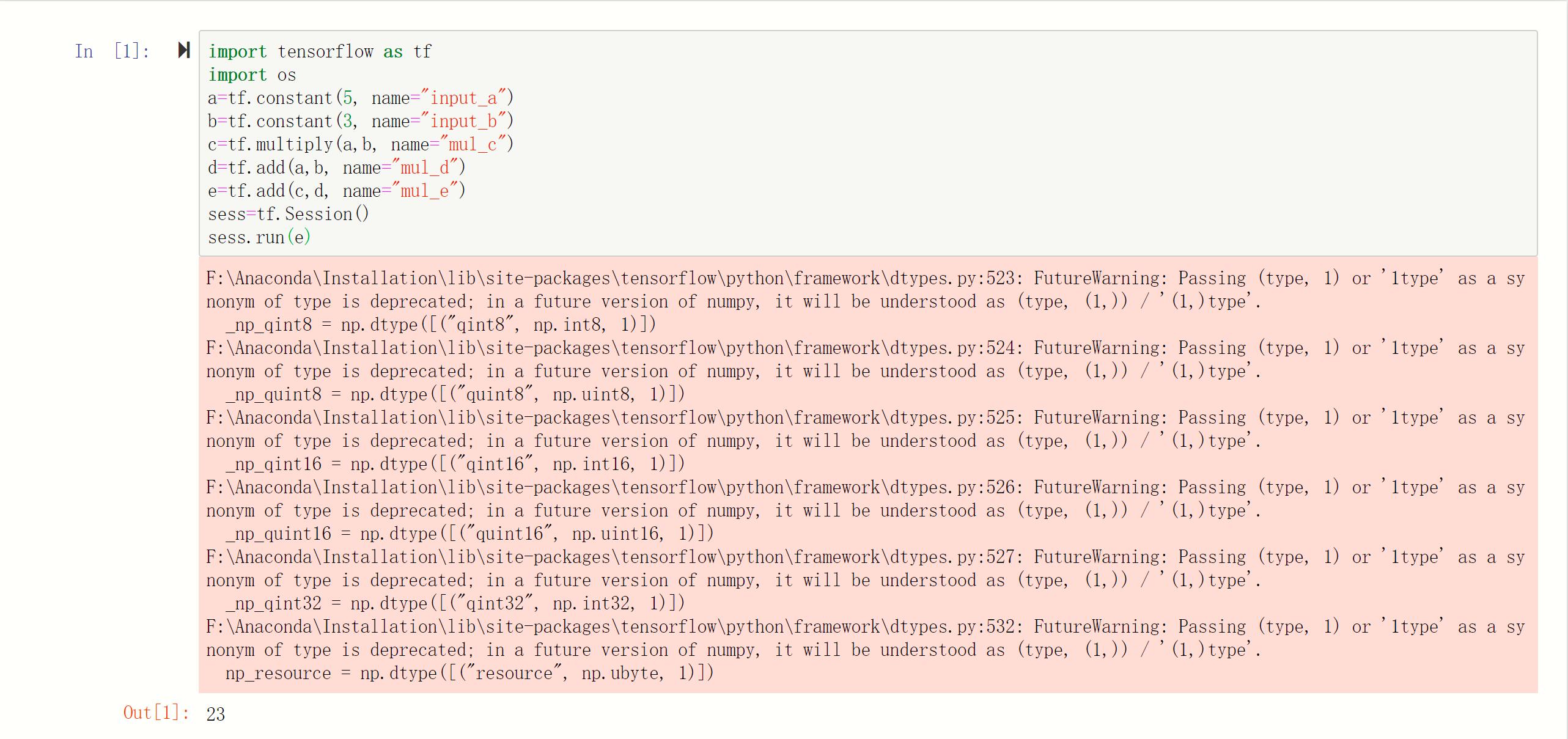
常见错误:
ImportError: cannnot import name pywrap_tensorflow
请确保交互环境不是从TensorFlow的源文件夹启动的。而如果得到一条类似下面的错误提示:
ImportError: No module name tensorflow
请复查TensorFlow是否被正确安装。如果使用的是Virtualenv或Conda,请确保启动交互式Python软件时,TensorFlow环境处于活动状态。 注意,如果运行了多个终端,则将只有一个终端拥有活动状态的TensorFlow环境。 如果对使用tf.mul和tf.add感到厌倦,不妨将其替换为tf.sub、tf.div或tf.mod,这些函数分别执行的是减法、除法和取模运算。 [tf.div](https://www.tensorflow.org/versions/master/api_docs/python/math_ops.html#div) 或者执行整数除法,或执行浮点数除法,具体取决于所提供的输入类型。如果希望确保使用浮点数除法,请使用tf.truediv。
2.2 关于InteractiveSession
tf.Session有一个与之十分相近的变体——tf.InteractiveSession。它是专为交互式Python软件设计的(例如那些可能正在使用的环境),而且它采取了一些方法使运行代码的过程更加简便。不利的方面是在Python文件中编写TensorFlow代码时用处不大,而且它会将一些作为TensorFlow新手应当了解的信息进行抽象。此外,它不能省去很多的按键次数。本文将始终使用标准的tf.Session类。 通过session调用,应该能够看到中间节点c的输出:
sess.run(c)
TensorFlow不会对你所创建的数据流图做任何假设,程序并不会关心节点c是否是你希望得到的输出!实际上,可对数据流图中的任意Op使用run()函数。当将某个Op传入sess.run()时,本质上是在通知TensorFlow“这里有一个节点,我希望得到它的输出,请执行所有必要的运算来求取这个节点的输出”。可反复尝试该函数的使用,将数据流图中其他节点的结果输出。 还可将运行数据流图所得到的结果保存下来。下面将节点e的输出保存到一个名为output的Python变量中:
output=sess.run(e)
对它进行可视化,以确认其结构与之前所绘制的数据流图完全一致。为此可使用TensorBoard,它是随TensorFlow一起安装的。为利用TensorBoard,需要在代码中添加下列语句:
writer=tf.train.SummaryWriter('./my_graph',sess.graph)
我们创建了一个TensorFlow的SummaryWriter对象,并将它赋给变量writer。虽然在此不准备用SummaryWriter对象完成其他操作,但今后会利用它保存来自数据流图的数据和概括统计量,因此我们习惯于将它赋给一个变量。 为对SummaryWriter对象进行初始化,我们传入了两个参数。第一个参数是一个字符串输出目录,即数据流图的描述在磁盘中的存放路径。在本例中,所创建的文件将被存放在一个名为my_graph的文件夹中,而该文件夹位于运行Python代码的那个路径下。我们传递给SummaryWriter构造方法的第二个输入是Session对象的graph属性。作为在TensorFlow中定义的数据流图管理器,tf.Session对象拥有一个graph属性,该属性引用了它们所要追踪的数据流图。通过将该属性传入SummaryWriter构造方法,所构造的SummarWriter对象便会将对该数据流图的描述输出到“my_graph”路径下。SummaryWriter对象初始化完成之后便会立即写入这些数据,因此一旦执行完这行代码,便可启动TensorBoard(确保当前工作路径与运行Python代码的路径一致):
tensorboard --logdir="my_graph"
从控制台中,应该能够看到一些日志信息打印出来,然后是消息“Starting Tensor-Board on port6066”。刚才所做的是启动一个使用来自“my_graph”目录下的数据的TensorBoard服务器。默认情况下,TensorBoard服务器启动后会自动监听端口6006——要访问TensorBoard,可打开浏览器并在地址栏输入http://localhost:6006 ,然后将看到一个橙白主题的欢迎页面.
请不要为警告消息“No scalar data was found”紧张,这仅仅表示我们尚未为Tensor-Board保存任何概括统计量,从而使其无法正常显示。通常,这个页面会显示利用SummaryWriter对象要求TensorFlow所保存的信息。由于尚未保存任何其他统计量,所以无内容可供显示。尽管如此,这并不妨碍我们欣赏自己定义的数据流图。单击页面顶部的“Graph”链接,将看到类似下图的页面:
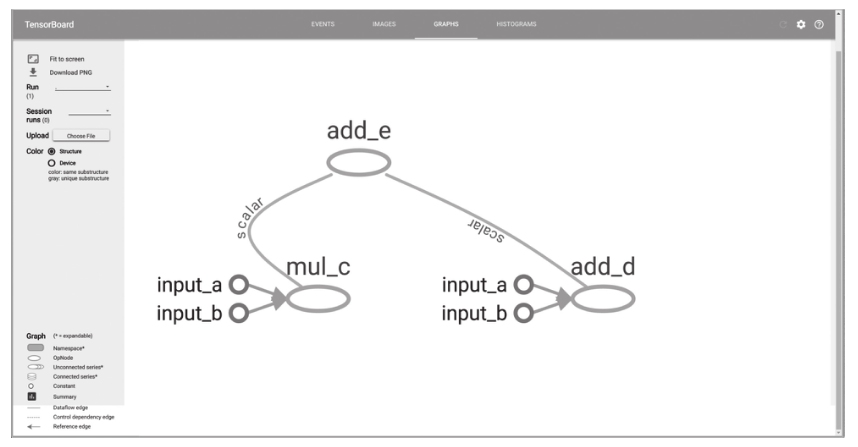 完成数据流图的构造之后,需要将Session对象和SummarWriter对象关闭,以释放资源并执行一些清理工作:
完成数据流图的构造之后,需要将Session对象和SummarWriter对象关闭,以释放资源并执行一些清理工作:
writer.close()
sess.close()
从技术角度讲,当程序运行结束后(若使用的是交互式环境,当关闭或重启Python内核时),Session对象会自动关闭。尽管如此,笔者仍然建议显式关闭Session对象,以避免任何诡异的边界用例的出现。